Conservative Equilibrium Discovery via Model-Based Uncertainty Quantification
Presented at AAMAS 2026
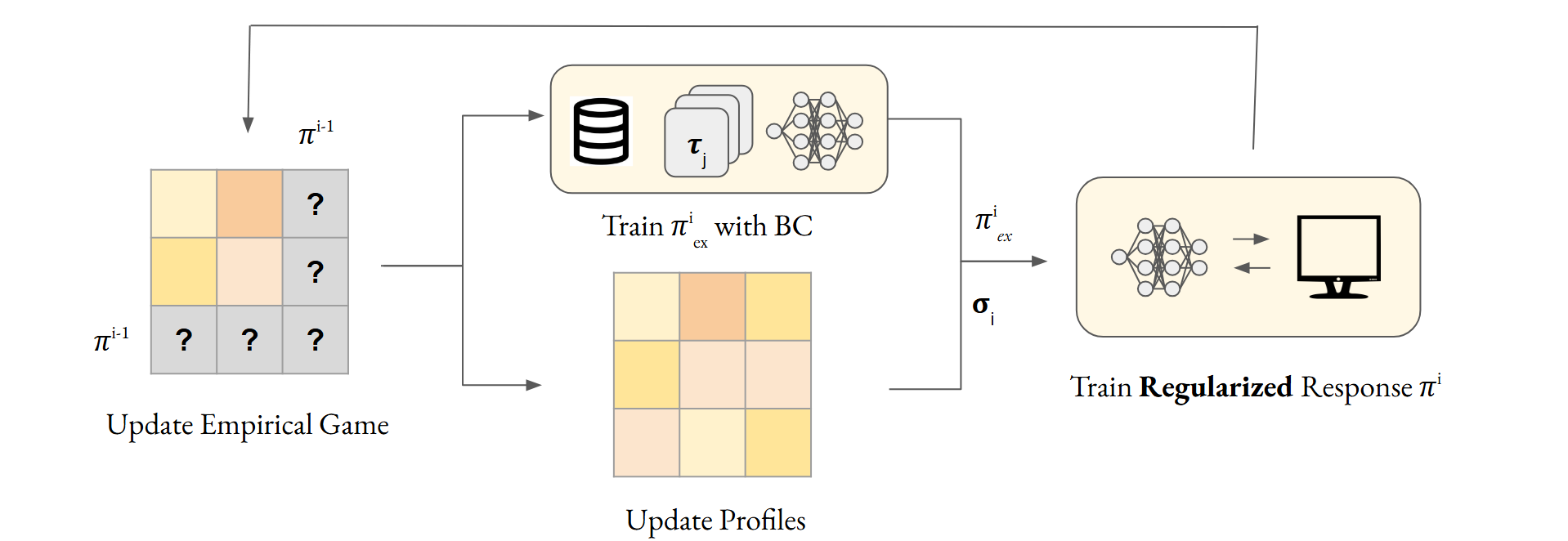
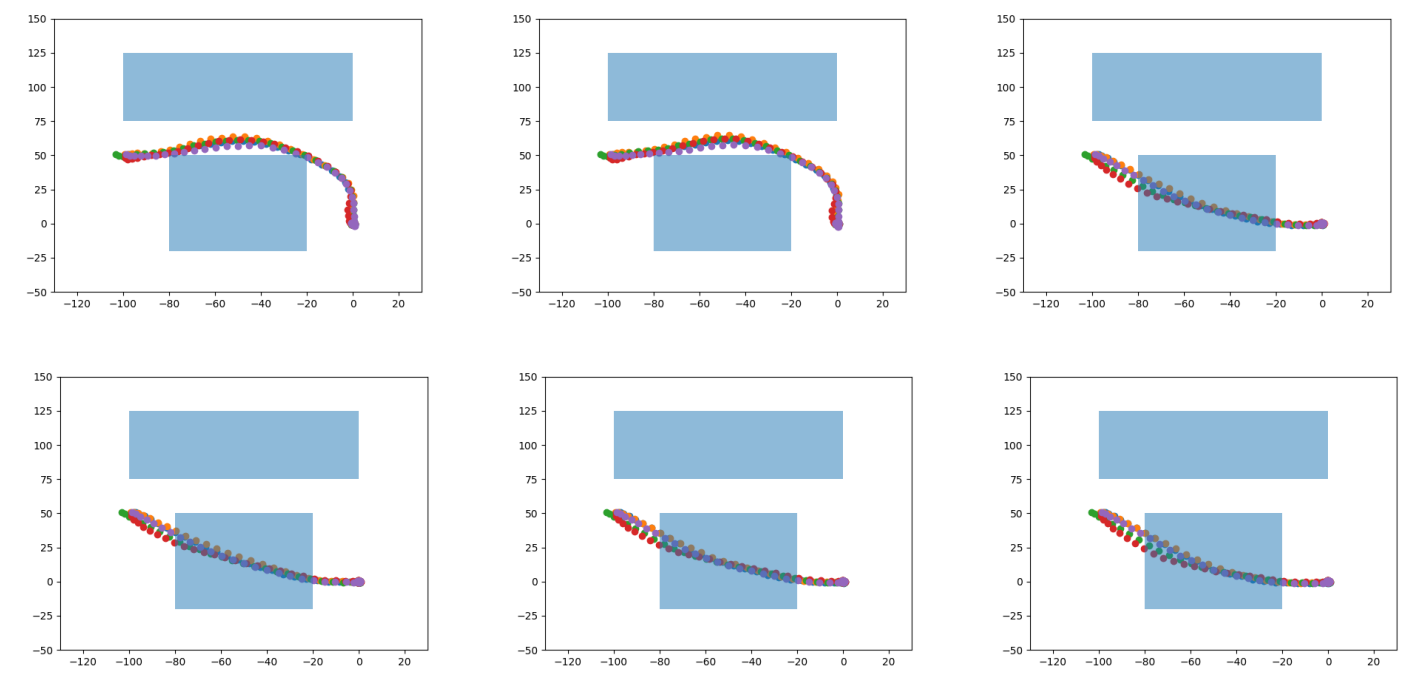
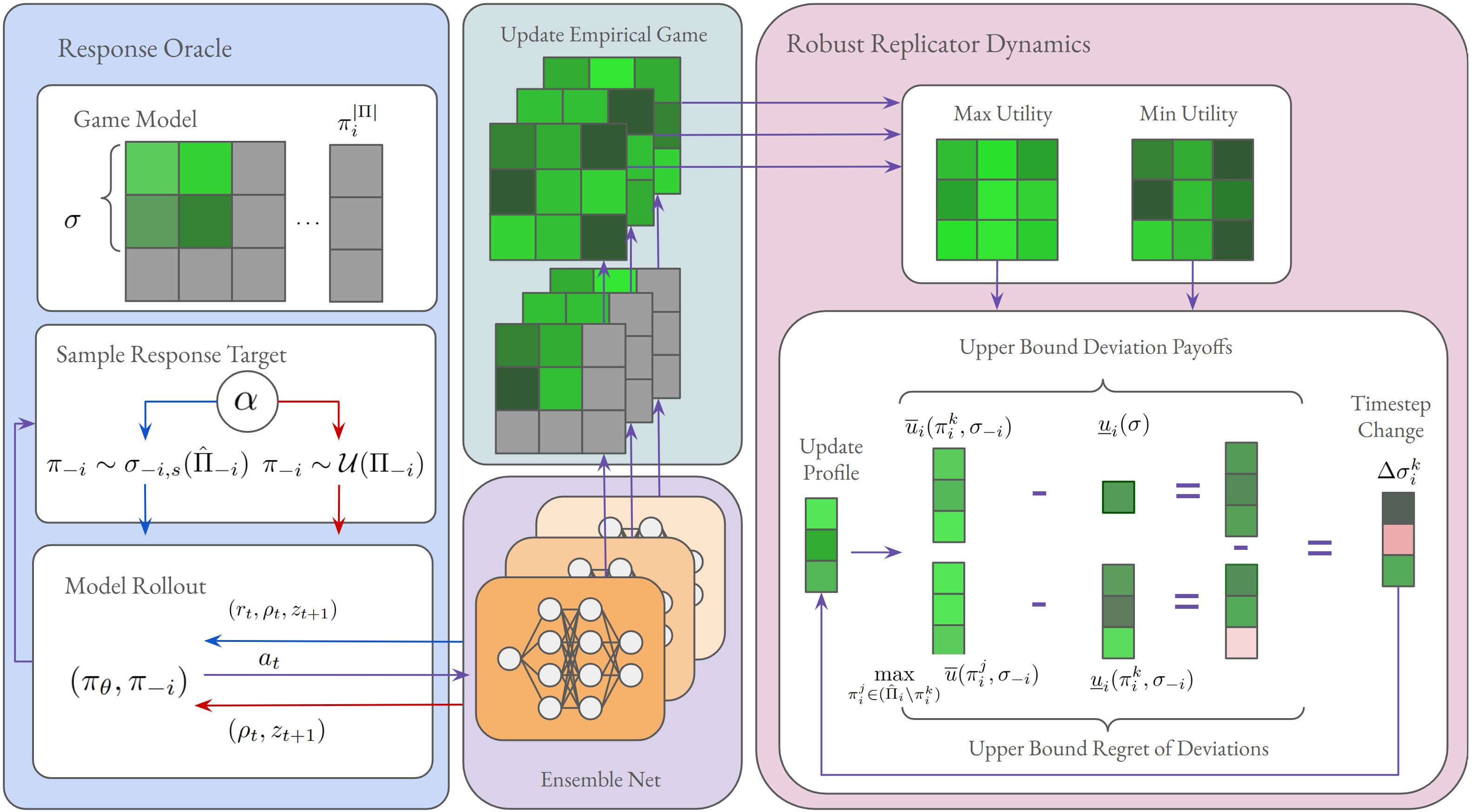
This paper presents a novel offline adaptation of PSRO, where game-solving is restricted to a fixed dataset of gameplay. Offline model-based "discrepancy" is used to encourage conservatism when training new strategies and determining response targets within PSRO.